

Making ML Training Carbon-Aware with Compute Gardener (Part 1)
How we reduced deferrable training jobs' carbon emissions by ~30% without changing a single line of code 📉🌿
The Problem: ML's Hidden Carbon Cost
Every day and all across the world, thousands of machine learning (ML) engineers and data scientists hit "submit" on their training or fine-tuning jobs. Whether "locally" or in a data center somewhere, graphics processing units (GPUs) spin up immediately, regardless of how clean the energy mix on the grid is at that place and time. Without intervention, execution time is dictated more so by the eccentricities and daily working patterns of teams than an optimal, carbon-aware strategy.
In this post, we'll document a recent experiment to limit model training carbon emissions, one that didn't require any human intervention after initial setup. For our purposes, a training job will involve training the ResNet50 model on the CIFAR-100 dataset for 30 epochs.
Truthfully, this isn't the most cutting edge nor demanding task in 2025... but it should provide a somewhat representative training workload which is "bite sized" and reproducible for demonstrating carbon-aware scheduling principles broadly.
A few details:
- A single ResNet50 training run 🤖 on one of our consumer grade cards (RTX 3090) consumes ~0.475 kWh of energy (~57 minutes at ~500W total system power). 🔥⚡
- That's enough energy to charge my partner's Electric SUV 🔋🛞 with about 1.5 miles of range.
- At higher grid intensity times (usually overnight in CalISO region) we can expect to see 300 or more gCO2eq/kWh vs 100 or fewer gCO2eq/kWh at lower intensity times (usually early afternoon). That crazy unit is "grams of carbon dioxide equivalent per kilowatt-hour".
- That can mean hundreds of grams of CO2 difference per run, solely due to execution time. I find it hard to make sense of this value, until I remember that I measure out only 15g of coffee beans to grind each morning. ☕🫘
While this experiment represents one engineer's jobs for a week, imagine it extrapolating out to hundreds of runs per team per month across many organizations... and the true magnitude of the opportunity to optimize training for carbon, with minimal hassle, starts to come into focus. 🔎🌐
Enter Temporal Shifting
What if deferrable training jobs could wait for cleaner energy? By "deferrable," we mean workloads where no human is waiting for immediate results and no downstream system is blocked on completion (ex: batch retraining, experimental model iterations, scheduled data processing pipelines, research experiments). These are fundamentally different from customer-facing inference services, APIs or real-time applications where milliseconds matter.
Meanwhile, the grid's carbon intensity varies by 2-3x throughout the day in many regions. Time shifting as a strategy is nothing new. It's been discussed and adopted for years, but there wasn't as much tooling to simplify and automate as there ought to have been. In particular, we were interested in a flexible and extensible approach using the Kubernetes scheduler plugin framework.
Key insight: Deferrable workloads + Time flexibility = Carbon savings. We're not talking about delaying production API responses, but rather the training jobs that could wait hours or even days for optimal conditions... but only if the friction and overhead of delaying them isn't too high.
Compute Gardener: A Secondary Scheduler for Kubernetes
Rather than asking engineers to change their workflows, what if we made the infrastructure itself carbon-aware? That's exactly what our open-source Kubernetes scheduler does.
What It Is
- A carbon-aware Kubernetes scheduler that runs alongside the default scheduler
- Evaluates real-time grid carbon intensity before scheduling
- Defers non-critical workloads to cleaner time windows
- Ensures jobs run within some maximum delay (configurable, defaults to 24hrs)
What It Isn't
- A replacement for your existing default scheduler; only workloads that explicitly opt-in are affected
- An approach requiring code modification (whether training, inference or batch processing code)
- A strategy that asks you to sacrifice reliability for sustainability
Real-World Testing: A Week of ML Training
To validate this approach, we designed a week-long experiment with semi-realistic training patterns, measuring both the carbon impact and operational effects of carbon-aware scheduling. This occurred 22nd-26th Sept '25.
The Workload
- Model: ResNet50 (25M parameters)
- Dataset: CIFAR-100 (100 classes, 50K training images)
- Hardware: Single RTX 3090 (24GB VRAM)
- Duration: ~1 hour per run
- Pattern: Each day we simulated a typical ML engineer's daily workflow with 4 job submissions representing common trigger points throughout the workday and overnight automation:
- Morning iteration: caffeine-fueled submission at 10:19am
- Afternoon collab: "last chance" before EOD submission at 5:41pm
- Midnight warrior: poor work-life balance induced submission at 11:12pm
- Overnight auto-infra: re-training triggered as part of data ingestion pipeline at 3:55am
The Setup
We know not everyone has ready access to a Kubernetes cluster, but very similar patterns could be applied in other cloud/HPC orchestrated environments or even on local workstations.
For those who are responsible for such cluster(s) (DevOps teams, lead engineers, other tech decision makers), the aim was to ensure our scheduler would be easy to get up and running quickly. After install, it should be ready to start mitigating real-world emissions immediately with minimal-to-no further configuration. Compute Gardener uses the Electricity Maps API for real-time carbon intensity data. The free tier works well for this experiment but is limited to accessing live data for only a single grid region.
# standard k8s Job requesting secondary scheduler
apiVersion: batch/v1
kind: Job
metadata:
name: ml-training-experiment
spec:
template:
spec:
# The only change needed ↓
schedulerName: compute-gardener-scheduler
containers:
- name: pytorch-training
image: pytorch/pytorch:2.1.0-cuda12.1-cudnn8-runtime
command:
- python
- /train.py
resources:
requests:
nvidia.com/gpu: 1
Note: This example is simplified for clarity. A real job would include volume mounts for your training script and data, possibly a ConfigMap for hyper-parameters and other standard Kubernetes configuration.
The Configuration
By default, the Compute Gardener (CG) Scheduler uses a 24hr maximum delay and 200 gCO2eq/kWh intensity threshold. These can both be easily overridden with custom pod annotations. But in the spirit of keeping the experiment simple and reproducible, we stuck with the defaults.
What happens when jobs queue up? If grid intensity stays high long enough, CG enforces a maximum delay (default 24hrs), so jobs will run even at higher intensity rather than miss their deadline. Think of it as a carbon budget with a safety valve, not a hard gate that could block critical work.
The Results
The results are promising, ~30% reduction in emissions... but they are also quite dependent on grid intensity and workload schedules. In CalISO, last week, with this pattern of jobs, we'd argue, the opportunity was large enough to warrant pursuing.
Note on geographic variation: These savings reflect CalISO's grid characteristics. While many grids now exhibit daily carbon intensity variation, the magnitude differs by region. Check Electricity Maps to assess your grid's potential. You'll likely see some real savings if your grid region has daily intensity swings of >100 gCO2eq/kWh and a threshold is chosen based on local grid region history.
Week Overview
- Work Week 22nd-26th of September 2025
- Total Jobs: 20 (4 each day) training runs simulating a few data science workflows
- Without CG: All would have run immediately at submission time
- With CG: Strategic delays based on real-time grid carbon intensity
Carbon Impact
| Metric | Without CG | With CG | Reduction |
|---|---|---|---|
| Avg Carbon Intensity | 231 gCO2eq/kWh | 165 gCO2eq/kWh | 29% |
| Total Emissions | 2.26 kgCO2eq | 1.63 kgCO2eq | 28% |
| Jobs Reducing Carbon | 0% | 55% | - |
| Avg Delay | 0 hours | 3.63 hours | - |
Since only 55% of the jobs encountered were delayed, those were the only ones reducing emissions. This value and the average delay duration per job are greatly influenced by how aggressively the intensity threshold and max delay are set.
Remember, all of this can scale up from workstations to data centers and beyond. The real goal is to show that compute can operate flexibly, in ways aligned to the grid and related signals.
Quick View
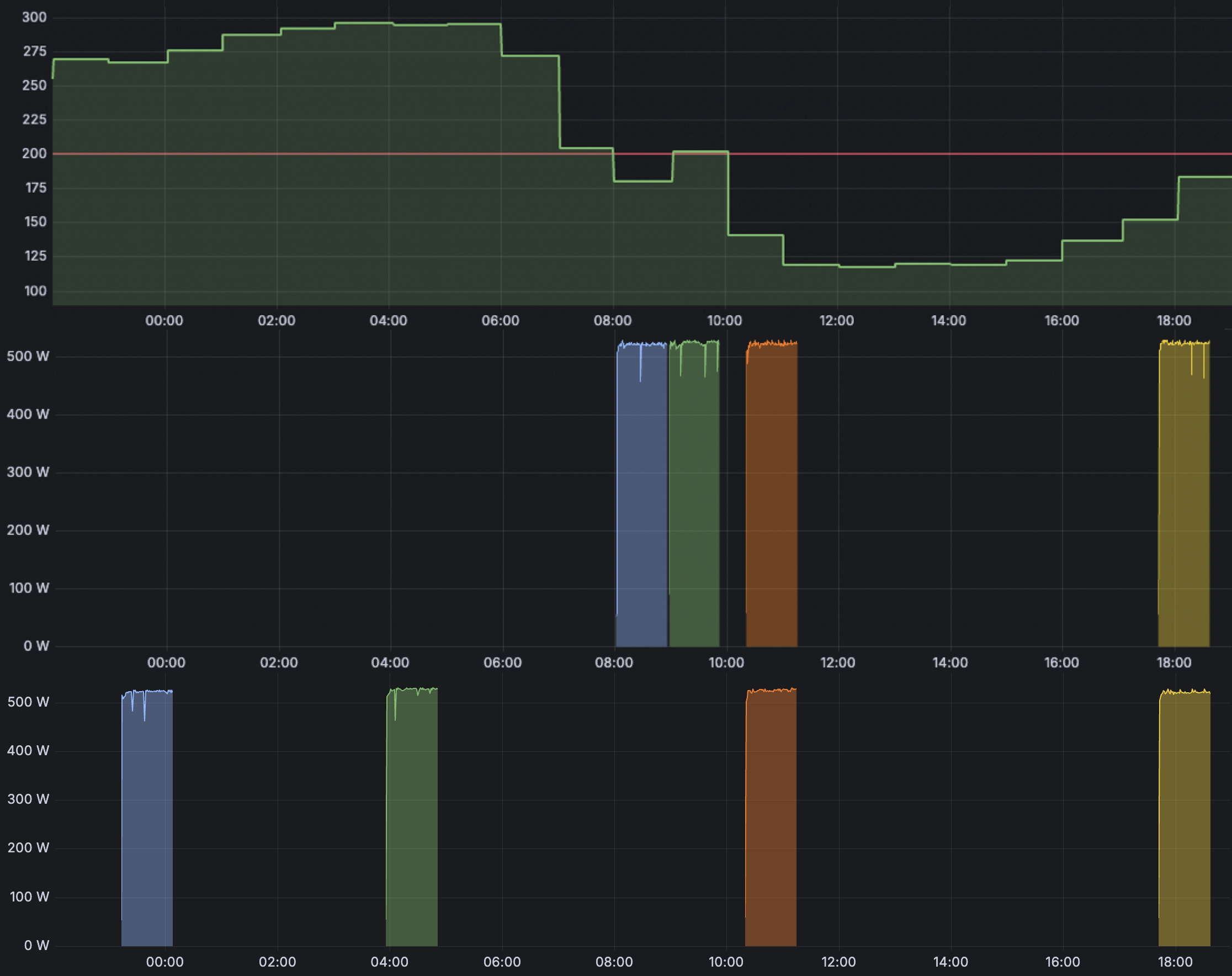
Figure 1: Grid carbon intensity (top), ComputeGardener shifted jobs (middle) and unshifted jobs (bottom) over nearly a day. Blue represents the midnight job, green the automated job, orange the morning job and yellow the end of day job.
Key Findings
Just considering this one week's worth of data, in CalISO region, we can say:
- Peak intensity hours (3-6 AM): Carbon intensity averaged ~350 gCO2eq/kWh
- Optimal windows (12-4 PM): Carbon intensity averaged ~120 gCO2eq/kWh
- Automation jobs: The best savings usually came from the overnight jobs, most often being delayed around 6 or 7 hrs, until the morning. For example, the greatest carbon savings for a job was 90.1 gCO2eq. It executed at 158 gCO2eq/kWh, 8.9 hours after it first appeared when the intensity was 351 gCO2eq/kWh.
- No failed jobs: 100% completion rate despite delays and no jobs hit their max delay
There's still a lot of low hanging fruit to pick here. Whereas this experiment, and Compute Gardener by default, uses a simple carbon intensity threshold, we'll soon be launching more sophisticated intensity forecast based logic. Essentially, rather than simply letting jobs execute as soon as intensity falls below a threshold, actually try to find the lowest intensity times, in the near future, to delay until.
Reproducibility
All experiment data, code and training scripts are available in our GitHub repo. We encourage you to reproduce these results in your own environment and share your findings.
Adoption: A couple minutes to Carbon Action
Step 1: Install Compute Gardener (One-time, 3 minutes)
# Add the Helm repository
helm repo add compute-gardener https://elevated-systems.github.io/compute-gardener-scheduler
helm repo update
# Standard installation - Requires Electricity Maps API key but works with FREE tier
helm install compute-gardener-scheduler compute-gardener/compute-gardener-scheduler \
--namespace compute-gardener \
--create-namespace \
--set carbonAware.electricityMap.apiKey=YOUR_API_KEY
Step 2: Leverage It (add per pod spec, 1 minute each)
spec:
schedulerName: compute-gardener-scheduler # That's it!
Step 3: [Optional] Fine-tuning
- Adjust carbon thresholds based on your grid region and workload urgency
- Set maximum delays that match your SLAs and persnickety engineers' expectations
- Configure time-of-use pricing awareness, if applicable in your environment
Beyond Simple Training: Production ML Pipelines
This sets the foundation for Part 2, where we'll explore a more complex and real-world training scenario
While ResNet training demonstrates the concept, this is just the beginning. In 2025, many organizations and enthusiasts are fine-tuning LLMs for domain-specific tasks and the carbon impact is massive. We're talking multi-GPU clusters running for hours or days... each job.
Next post: LLM LoRA Fine-tuning with Ray + Compute Gardener—how we made LLM training carbon-aware, handling workloads that represent the cutting edge of today's ML infrastructure. If you're fine-tuning models with (Kube)Ray, you won't want to miss this!
Interested in implementing something similar in your organization?
If automated carbon awareness for your ML infrastructure sounds appealing, we're available to help. Whether you're looking to deploy Compute Gardener, customize it for your use case or explore advanced carbon optimization strategies, our consulting services team can guide you through the process. Don't hesitate to reach out - let's work together to advance sustainable computing practices.
Have questions about implementation? Check our FAQ page for answers to common questions about installation, configuration, and best practices.
Compute Gardener is an open-source Kubernetes scheduler that enables carbon-aware workload scheduling across hybrid clouds. Join us in making carbon-aware computing the default, not the exception.